Sun, 10 Sep 2017
PR 219251
As I threatened to do in my previous post, I'm going to talk about
PR
219251 for a bit.
The bug report dates from only a few months ago, but the first report (that I
can remeber) actually came from Shawn Webb on Twitter, of all
places:
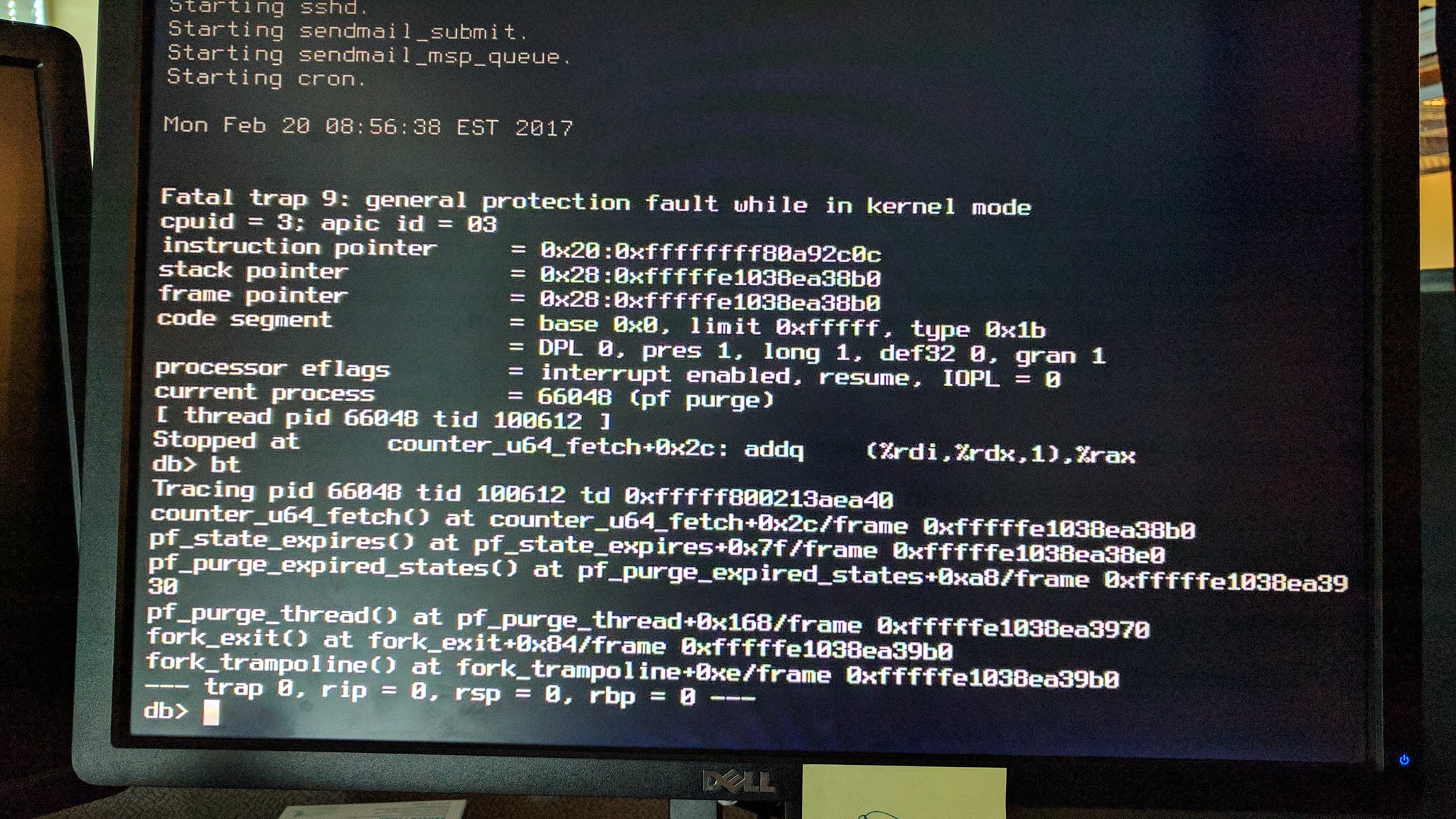
Despite there being a stacktrace it took quite a while (nearly 6 months in fact) before I figured this one out.
It took Reshad Patuck managing to distill the problem down to a small-ish test script to make real progress on this. His testcase meant that I could get core dumps and experiment. It also provided valuable clues because it could be tweaked to see what elements were required to trigger the panic.
This test script starts a (vnet) jail, adds an epair interface to it, sets up pf in the jail, and then reloads the pf rules on the host. Interestingly the panic does not seem to occur if that last step is not included.
Time to take a closer look at the code that breaks:
u_int32_t
pf_state_expires(const struct pf_state *state)
{
u_int32_t timeout;
u_int32_t start;
u_int32_t end;
u_int32_t states;
/* handle all PFTM_* > PFTM_MAX here */
if (state->timeout == PFTM_PURGE)
return (time_uptime);
KASSERT(state->timeout != PFTM_UNLINKED,
("pf_state_expires: timeout == PFTM_UNLINKED"));
KASSERT((state->timeout < PFTM_MAX),
("pf_state_expires: timeout > PFTM_MAX"));
timeout = state->rule.ptr->timeout[state->timeout];
if (!timeout)
timeout = V_pf_default_rule.timeout[state->timeout];
start = state->rule.ptr->timeout[PFTM_ADAPTIVE_START];
if (start) {
end = state->rule.ptr->timeout[PFTM_ADAPTIVE_END];
states = counter_u64_fetch(state->rule.ptr->states_cur);
} else {
start = V_pf_default_rule.timeout[PFTM_ADAPTIVE_START];
end = V_pf_default_rule.timeout[PFTM_ADAPTIVE_END];
states = V_pf_status.states;
}
if (end && states > start && start < end) {
if (states < end)
return (state->expire + timeout * (end - states) /
(end - start));
else
return (time_uptime);
}
return (state->expire + timeout);
}
Specifically, the following line:
states = counter_u64_fetch(state->rule.ptr->states_cur);
We try to fetch a counter value here, but instead we dereference a bad pointer. There's two here, so already we need more information. Inspection of the core dump reveals that the state pointer is valid, and contains sane information. The rule pointer (rule.ptr) points to a sensible location, but the data is mostly 0xdeadc0de. This is the memory allocator being helpful (in debug mode) and writing garbage over freed memory, to make use-after-free bugs like this one easier to find.
In other words: the rule has been free()d while there was still a state pointing to it. Somehow we have a state (describing a connection pf knows about) which points to a rule which no longer exists.
The core dump also shows that the problem always occurs with states and rules in the default vnet (i.e. the host pf instance), not one of the pf instances in one of the vnet jails. That matches with the observation that the test script does not trigger the panic unless we also reload the rules on the host.
Great, we know what's wrong, but now we need to work out how we can get into this state. At this point we're going to have to learn something about how rules and states get cleaned up in pf. Don't worry if you had no idea, because before this bug I didn't either.
The states keep a pointer to the rule they match, so when rules are changed (or removed) we can't just delete them. States get cleaned up when connections are closed or they time out. This means we have to keep old rules around until the states that use them expire.
When rules are removed pf_unlink_rule() adds then to the V_pf_unlinked_rules list (more on that funny V_ prefix later). From time to time the pf purge thread will run over all states and mark the rules that are used by a state. Once that's done for all states we know that all rules that are not marked as in-use can be removed (because none of the states use it).
That can be a lot of work if we've got a lot of states, so pf_purge_thread() breaks that up into smaller chuncks, iterating only part of the state table on every run. Let's look at that code:
void
pf_purge_thread(void *unused __unused)
{
VNET_ITERATOR_DECL(vnet_iter);
u_int idx = 0;
sx_xlock(&pf_end_lock);
while (pf_end_threads == 0) {
sx_sleep(pf_purge_thread, &pf_end_lock, 0, "pftm", hz / 10);
VNET_LIST_RLOCK();
VNET_FOREACH(vnet_iter) {
CURVNET_SET(vnet_iter);
/* Wait until V_pf_default_rule is initialized. */
if (V_pf_vnet_active == 0) {
CURVNET_RESTORE();
continue;
}
/*
* Process 1/interval fraction of the state
* table every run.
*/
idx = pf_purge_expired_states(idx, pf_hashmask /
(V_pf_default_rule.timeout[PFTM_INTERVAL] * 10));
/*
* Purge other expired types every
* PFTM_INTERVAL seconds.
*/
if (idx == 0) {
/*
* Order is important:
* - states and src nodes reference rules
* - states and rules reference kifs
*/
pf_purge_expired_fragments();
pf_purge_expired_src_nodes();
pf_purge_unlinked_rules();
pfi_kif_purge();
}
CURVNET_RESTORE();
}
VNET_LIST_RUNLOCK();
}
pf_end_threads++;
sx_xunlock(&pf_end_lock);
kproc_exit(0);
}
We iterate over all of our virtual pf instances (VNET_FOREACH()), check if it's active (for FreeBSD-EN-17.08, where we've seen this code before) and then check the expired states with pf_purge_expired_states(). We start at state 'idx' and only process a certain number (determined by the PFTM_INTERVAL setting) states. The pf_purge_expired_states() function returns a new idx value to tell us how far we got.
So, remember when I mentioned the odd V_ prefix? Those are per-vnet variables. They work a bit like thread-local variables. Each vnet (virtual network stack) keeps its state separate from the others, and the V_ variables use a pointer that's changed whenever we change the currently active vnet (say with CURVNET_SET() or CURVNET_RESTORE()). That's tracked in the 'curvnet' variable. In other words: there are as many V_pf_vnet_active variables as there are vnets: number of vnet jails plus one (for the host system).
Why is that relevant here? Note that idx is not a per-vnet variable, but we handle multiple pf instances here. We run through all of them in fact. That means that we end up checking the first X states in the first vnet, then check the second X states in the second vnet, the third X states in the third and so on and so on.
That of course means that we think we've run through all of the states in a vnet while we really only checked some of them. So when pf_purge_unlinked_rules() runs it can end up free()ing rules that actually are still in use because pf_purge_thread() skipped over the state(s) that actually used the rule.
The problem only happened if we reloaded rules in the host jail, because the active ruleset is never free()d, even if there are no states pointing to the rule.
That explains the panic, and the fix is actually quite straightforward: idx needs to be a per-vnet variable, V_pf_purge_idx, and then the problem is gone.
As is often the case, the solution to a fairly hard problem turns out to be really simple.
posted at: 19:00 | path: /freebsd | [ 0 comments ]
Sat, 02 Sep 2017
FreeBSD-EN-17:08.pf
Allan twisted my arm in BSDNow episode 209 so I'll have to talk about FreeBSD-EN-17:08.pf.
First things first, so I have to point out that I think Allan misremembered things. The heroic debugging story is PR 219251, which I'll try to write about later.
FreeBSD-EN-17:08.pf is an issue that affected some FreeBSD 11.x systems, where FreeBSD would panic at startup. There were no reports for CURRENT. That looked like this:
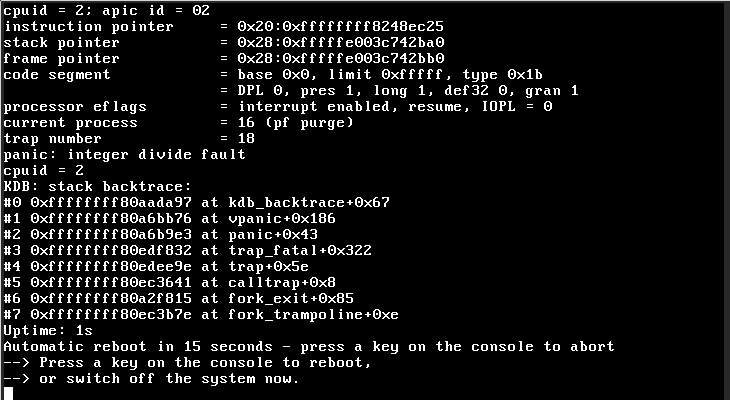
There's very little to go on here, but we do now the cause of the panic ("integer divide fault"), and that the current process was "pf purge". The pf purge thread is part of the pf housekeeping infrastructure. It's a housekeeping kernel thread which cleans up things like old states and expired fragments.
Here's the core loop:
void
pf_purge_thread(void *unused __unused)
{
VNET_ITERATOR_DECL(vnet_iter);
u_int idx = 0;
sx_xlock(&pf_end_lock);
while (pf_end_threads == 0) {
sx_sleep(pf_purge_thread, &pf_end_lock, 0, "pftm", hz / 10);
VNET_LIST_RLOCK();
VNET_FOREACH(vnet_iter) {
CURVNET_SET(vnet_iter);
/*
* Process 1/interval fraction of the state
* table every run.
*/
idx = pf_purge_expired_states(idx, pf_hashmask /
(V_pf_default_rule.timeout[PFTM_INTERVAL] * 10));
/*
* Purge other expired types every
* PFTM_INTERVAL seconds.
*/
if (idx == 0) {
/*
* Order is important:
* - states and src nodes reference rules
* - states and rules reference kifs
*/
pf_purge_expired_fragments();
pf_purge_expired_src_nodes();
pf_purge_unlinked_rules();
pfi_kif_purge();
}
CURVNET_RESTORE();
}
VNET_LIST_RUNLOCK();
}
pf_end_threads++;
sx_xunlock(&pf_end_lock);
kproc_exit(0);
}
The lack of mention of pf functions in the backtrace is a hint unto itself. It suggests that the error is probably directly in pf_purge_thread(). It might also be in one of the static functions it calls, because compilers often just inline those so they don't generate stack frames.
Remember that the problem is an "integer divide fault". How can integer divisions be a problem? Well, you can try to divide by zero. The most obvious suspect for this is this code:
idx = pf_purge_expired_states(idx, pf_hashmask / (V_pf_default_rule.timeout[PFTM_INTERVAL] * 10));
However, this variable is both correctly initialised (in pfattach_vnet()) and can only be modified through the DIOCSETTIMEOUT ioctl() call and that one checks for zero.
At that point I had no idea how this could happen, but because the problem did not affect CURRENT I looked at the commit history and found this commit from Luiz Otavio O Souza:
Do not run the pf purge thread while the VNET variables are not initialized, this can cause a divide by zero (if the VNET initialization takes to long to complete). Obtained from: pfSense Sponsored by: Rubicon Communications, LLC (Netgate)
That sounds very familiar, and indeed, applying the patch fixed the problem. Luiz explained it well: it's possible to use V_pf_default_rule.timeout before it's initialised, which caused this panic.
To me, this reaffirms the importance of writing good commit messages: because Luiz mentioned both the pf purge thread and the division by zero I was easily able to find the relevant commit. If I hadn't found it this fix would have taken a lot longer.
posted at: 19:00 | path: /freebsd | [ 0 comments ]
Thu, 27 Mar 2014
Bug reports
I've noticed that many testers, project/program/product managers, ... have no idea on how to properly report bugs, or request new features.
It's well known that developers will do everything they can to avoid actually writing code, so it's vitally important to avoid falling for their traps when reporting a bug. My fellow developers will be angry with me for giving away this secret information, but, well, it wants to be free!
Here are a few hints:
-
If you have multiple products or configurations avoid telling the developer which one you're talking about. This forces him to verify and fix all of them. If you're naive enough to specify the product he won't fix any of the others if they happen to be affected as well.
-
Sometimes a picture doesn't say quite as much as a thousand words. There are two schools of thought: the large and the small.
The first option is to make sure the screenshot includes everything: your complete desktop, your e-mail client, the application, your second monitor full of goat pornography and bonzi-buddy, ...
Ideally you'd save this screenshot as an uncompressed bitmap so it's at least 150MB in size. Don't let it be said that you didn't provide any information. 150MB is a lot of information!
For bonus points, use a video closeup of the screen. Close enough that you can see the individual pixels. Now that's a detailed report.The second option is to include only the error message. Preferably focussed on the message box with the error message, if possibly cutting off most of the error message itself. A true master will only include the exclamation mark, skull & bones, or other icon.
Focus on the essentials! Compress this screenshot mercilessly. Make sure it's completely unreadable.
File lots and lots of bugs. If, for example, your application has four modes dealing with frobnicks and all four nick before frobbing rather than frobbing and then nicking make sure you file four bugs. There's no way these problems are related and could be tracked in the same bug.
-
Make sure to remind the developer that he's supposed to fix the problem. If you report a crash don't forget to tell him that the application is not supposed to crash. If you don't he'll just claim that this is normal, and do nothing.
Include as little information as possible in the bug report. Developers are like kittens. They have a very short attention span and are easily... ooh! A shiny!
If the application spouts a load of incomprehensible gibberish when it crashes whatever you do, don't include that information in the bug report! You don't understand what it means, so there's no way the developer will understand it either. Making him feel stupid isn't going to get your problem fixed any quicker.
Besides, he's a developer, if he was smart he'd have a real job.-
Whatever you do, do not follow up on requests for more information. Asking for more information is a favorite trick of programmers to avoid having to work on the problem. Don't fall for it, don't give him the excuse, so just ignore the request completely.
If the programmer is very experienced and lazy he might go as far as assigning the bug report back to you. Again, don't fall for that, but give him hell about being so lazy! Demand to know why he thinks he can assign bugs to you! His job is closing bugs, not assigning them! Whatever you do, do not give him more information.
-
If cornered, as a last resort, you can offer more information, but even then you can be crafty: make sure the follow-up information contradicts the original report.
-
Offer as much context as possible: make vague allusions to remarks made by a third party, in which no developer was present. You know what you mean, he should know too.
-
Whatever you do, don't attach logs files to the bug report. Instead, keep them somewhere the developer won't find them, so you have some evidence on hand to prove that he's not helping you.
Certainly don't attach logs if the bug is hard to reproduce, or only occurs rarely. The developer would have to wade though thousands of log lines and would never get round to actually fixing the bug!
Developers just *love* reading 'Time under test: +/- 700hours' in a bug report with basically no other details!
Ignore increasingly desperate requests for log files. They're just another form of the request for more information. As soon as you respond you validate the developer's excuse for not actually fixing the bug.
In conclusion, the ideal bug report is "It breaky. You fix.".
In case someone doesn't get it, the above suggestions are NOT something you should do in bug reports. Unfortunately just about all of these are based on one or more bug reports I have received over the years.
posted at: 22:22 | path: /rant | [ 0 comments ]
Sun, 29 Dec 2013
Hotmail
No, I don't use them, but sometimes I send e-mail to people who do. It turns out that they don't like my e-mail. It sends up in the spam bucket.
After finding someone with a little clue who still remembered having a hotmail address I obtained the headers for one of my mails. It had this in it:
Authentication-Results: hotmail.com; spf=temperror ...
The OpenSPF
people explain what this means:
Hotmail does not use live DNS for Sender ID. They have a DNS cache that they
update twice per day. All TempError means is that your domain's SPF record is
not in their cache. To get your record added to their cache, send an e-mail
message to senderid@microsoft.com with your domain in it. They will add it,
but be patient as it's a manual process and the cache only updates twice a
day.
It appears that Microsoft don't even understand DNS (or e-mail). Why does that still surprise me?
posted at: 16:42 | path: /rant | [ 0 comments ]
Sun, 26 May 2013
AsciiDoc is great, but...
I was recently(-ish) introduced to AsciiDoc by a rather strange individual.
Suffice to say I've pretty much fallen in love with it. It pretty much mirrors the way I type plain text documentation, but it manages to generate quite pretty HTML output. All of the advantages of plain text (I get to use Vim, version control Just Works, ...), with only one downside: no previews of what I'm doing.
So I did something about that: qinotify is a small Qt utility which monitors .asciidoc files with for changes, and displays the latest version of the HTML output.
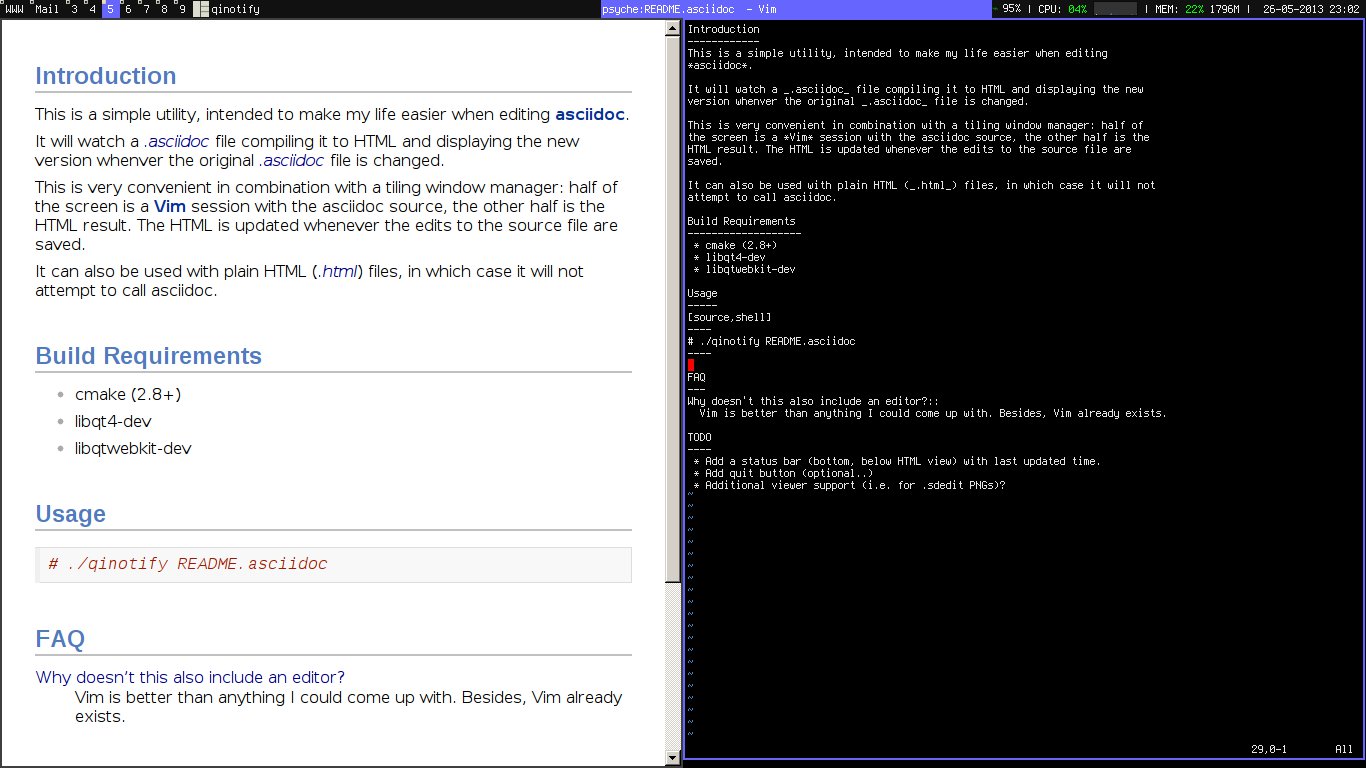
posted at: 23:12 | path: / | [ 3 comments ]
Wed, 06 Mar 2013
Sometime I hate Google
Sometimes I hate Google, or at least their mail admins. They seem to have entirely missed the point of SPF records.
I publish them, not because I believe they'll fix the spam problem, but because
a spammer has taken to forging their sender address to appear to originate from
my domain. Obviously none of my servers are involved in such loathsome activities.
I publish these records to give other mail admins the chance to reject such
e-mail outright, or at least to assign it a higher spam probability but mostly
so they won't bug me about having rejected it.
Google rather seem to have missed the point though because they use them to reject the spam, which is good, and then send delivery failures to me. They know that it's spam with a forged sender, that's why they're rejecting it in the first place, yet they bug me about it.
Delivery to the following recipient failed permanently:
efqrbsuglyjfuhxy3uca3w1b@jbinup.com
----- Original message -----
X-Received: by 10.68.42.9 with SMTP id j9mr23765326pbl.142.1362320729989;
Sun, 03 Mar 2013 06:25:29 -0800 (PST)
Return-Path:
Received: from [41.143.193.146] ([41.143.193.146])
by mx.google.com with ESMTP id tv4si18179919pbc.155.2013.03.03.06.25.24;
Sun, 03 Mar 2013 06:25:29 -0800 (PST)
Received-SPF: fail (google.com: domain of B37FBAB0D@sigsegv.be does not designate 41.143.193.146 as permitted
+sender) client-ip=41.143.193.146;
Authentication-Results: mx.google.com;
spf=hardfail (google.com: domain of B37FBAB0D@sigsegv.be does not designate 41.143.193.146 as permitted s
+ender) smtp.mail=B37FBAB0D@sigsegv.be
From: "Tanya Guerrero"
Subject: hi there
To:
List-Unsubscribe:
Content-Transfer-Encoding: 8bit
Content-Type: text/plain; chars="iso-8859-1"
Date: Sun, 03 Mar 2013 14:25:21 -0000
Message-ID: <20130303142521.244356B88AC8AC5DC029.4744484@SARA-PC>
SPAM SPAM SPAM
posted at: 19:59 | path: / | [ 0 comments ]
Sun, 06 May 2012
Open sores
After complaining about Microsoft last time I figured I'd do something different this time: I'm going to complain about a piece of open source software.
It needs no introduction, but I'll give it one anyway:
The ISC DHCP server and client are the standard DHCP(v4/v6)
implementations and they're used all over the place.
Recently I was fixing a bug in a dhclient-script.sh. It incorrectly
parsed an IAID value because it contained an '='.
The relevant bits of source code:
ient_envadd(client, prefix, "iaid", "%s", print_hex_1(4, ia->iaid, 12));This just adds the IAID value to the environment encoded, you'd expect, as a hex string.
Hang on? Hex string? Didn't I just say that we got an '=' in the data?
Looking a little deeper there's the first disturbing bit:
#define print_hex_1(len, data, limit) print_hex(len, data, limit, 0) #define print_hex_2(len, data, limit) print_hex(len, data, limit, 1) #define print_hex_3(len, data, limit) print_hex(len, data, limit, 2)Umm, ok then.
#define HBLEN 1024
char *print_hex(len, data, limit, buf_num)
unsigned len;
const u_int8_t *data;
unsigned limit;
unsigned buf_num;
{
static char hex_buf_1[HBLEN + 1];
static char hex_buf_2[HBLEN + 1];
static char hex_buf_3[HBLEN + 1];
char *hex_buf;
switch(buf_num) {
case 0:
hex_buf = hex_buf_1;
if (limit >= sizeof(hex_buf_1))
limit = sizeof(hex_buf_1);
break;
case 1:
hex_buf = hex_buf_2;
if (limit >= sizeof(hex_buf_2))
limit = sizeof(hex_buf_2);
break;
case 2:
hex_buf = hex_buf_3;
if (limit >= sizeof(hex_buf_3))
limit = sizeof(hex_buf_3);
break;
default:
return(NULL);
}
print_hex_or_string(len, data, limit, hex_buf);
return(hex_buf);
}
Wait what? What's with the three static buffers?
It's an evil, and stupid little trick to avoid having to supply a buffer from the caller. That's why there's a static buffer: the caller can just use the returned pointer without having to worry about freeing allocated memory.
There's three of them because presumably at some point someone tried to convert two strings before printing them and discovered that only both always had the same content when he used the output. Instead of solving the problem properly he decided to use this disgusting hack instead.
That's bad, but what about print_hex_or_string?
/*
* print a string as either text if all the characters
* are printable or colon separated hex if they aren't
*
* len - length of data
* data - input data
* limit - length of buf to use
* buf - output buffer
*/
void print_hex_or_string (len, data, limit, buf)
unsigned len;
const u_int8_t *data;
unsigned limit;
char *buf;
{
unsigned i;
if ((buf == NULL) || (limit < 3))
return;
for (i = 0; (i < (limit - 3)) && (i < len); i++) {
if (!isascii(data[i]) || !isprint(data[i])) {
print_hex_only(len, data, limit, buf);
return;
}
}
buf[0] = '"';
i = len;
if (i > (limit - 3))
i = limit - 3;
memcpy(&buf[1], data, i);
buf[i + 1] = '"';
buf[i + 2] = 0;
return;
}
Well, that's about as bad as the function name sounded. This converts the supplied data
into a string, either by interpreting it as plain ASCII (if all of the bytes are printable),
or converting it into a real hex string.
Enjoy yourself parsing that. Writing parsing and validation code is so much fun and now you get to do it twice!
posted at: 23:22 | path: / | [ 1 comments ]
Thu, 22 Dec 2011
A brief rant.
Observe the NdisAllocateMemoryWithTagPriority[1] function.
PVOID NdisAllocateMemoryWithTagPriority( __in NDIS_HANDLE NdisHandle, __in UINT Length, __in ULONG Tag, __in EX_POOL_PRIORITY Priority );
Read the documentation:
Tag [in]
A string, delimited by single quotation marks, with up to four characters, usually specified in reversed order.
The NDIS-supplied default tag for this call is 'maDN', but the caller can override this default by supplying an explicit value.
That's right. Pass that string as a ULONG please. I just don't have the words.
[1]Think kmalloc, but harder to type.
posted at: 13:20 | path: / | [ 0 comments ]
Sun, 21 Aug 2011
World IPv6 day
A little while ago (well, a long while, but I've been busy) the Internet Society organised World IPv6 day.
I'm not going to bother explaining what that was about, I'm sure everyone knows by now. Instead, I'm going to complain about a little experiment I did more than three years ago. Hopefully all the buzz around World IPv6 day and the IANA pool exhaustion has encouraged a few more people to offer their blog over modern IPv6, in addition to crusty old IPv4.
The results are, ... well, results. Three years ago there was one blog in Planet Grep which
was reachable on the IPv6 internet. This blog is still there (though with a different IP)
and there's all of four more. That's 5 out of 69, or 7.24%.
Just for fun I reran the test on the current list of blogs on Planet Grep. 7 of 97
sites, or 7.21% have an IPv6 address.
Not exactly great that. On the bright side: at least the sites which advertise quad-A records
are indeed reachable on those addresses, and the one site which had an IPv6 address
back in 2008 still has one.
Come on guys (and girls obviously), we can do better than this.
posted at: 16:45 | path: / | [ 0 comments ]
Sun, 12 Dec 2010
Change is a constant
Just in case I haven't told everyone yet, I'll be leaving my current employer mid January. From then on I'll be freelancing. I've already got a website and everything. (Well, not everything. In fact, just the website, but the rest is being worked on.)
Why? Well, two reasons really, the first is that a really interesting project and the second is the bad influence of a few friends.
If you have a problem, if no one else can help, ...
Well, you should probably call the A-Team,
but you've got a software problem you should call me. The A-Team doesn't know anything about software.
posted at: 23:06 | path: / | [ 4 comments ]