Sun, 10 Sep 2017
PR 219251
As I threatened to do in my previous post, I'm going to talk about
PR
219251 for a bit.
The bug report dates from only a few months ago, but the first report (that I
can remeber) actually came from Shawn Webb on Twitter, of all
places:
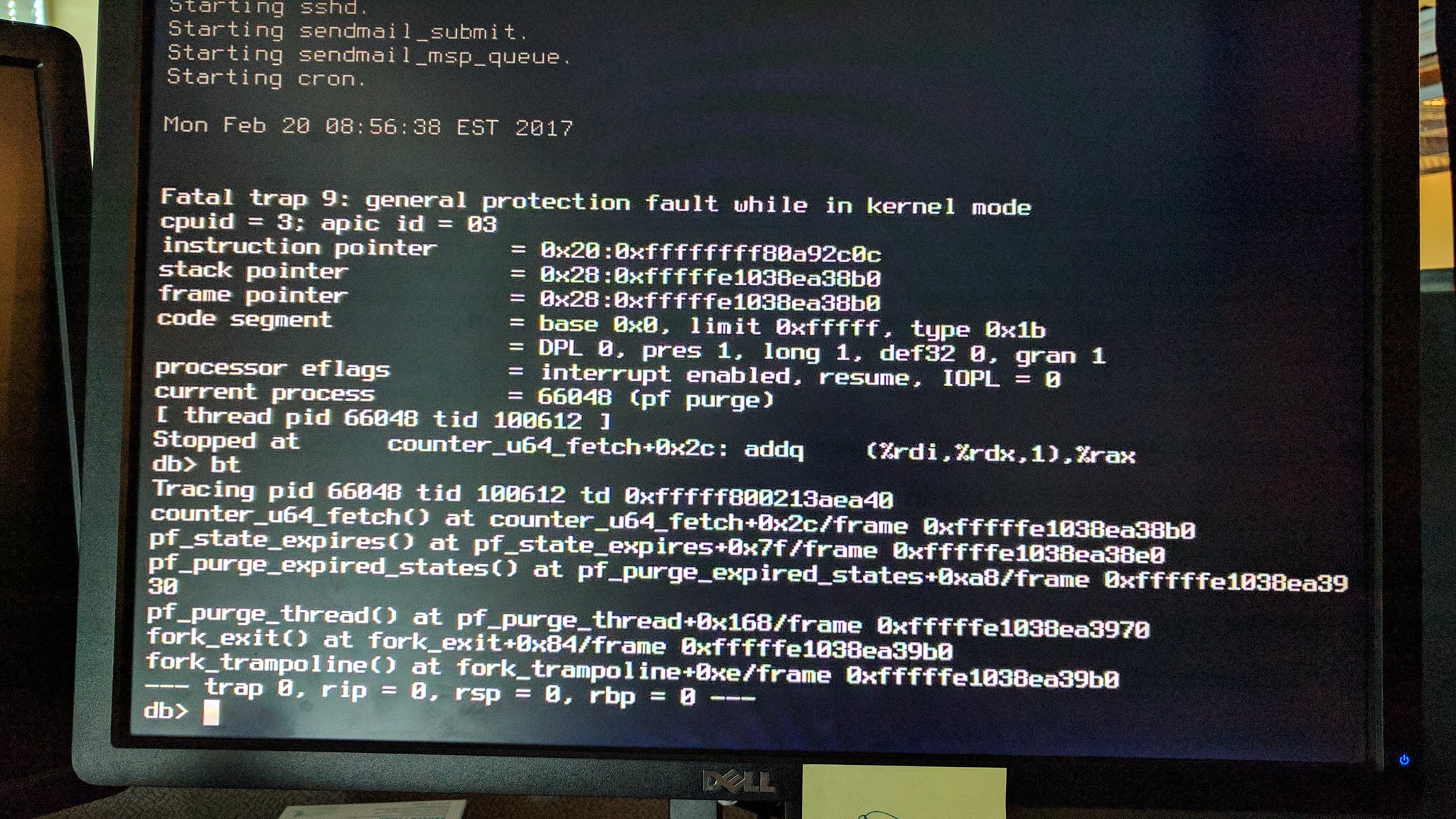
Despite there being a stacktrace it took quite a while (nearly 6 months in fact) before I figured this one out.
It took Reshad Patuck managing to distill the problem down to a small-ish test script to make real progress on this. His testcase meant that I could get core dumps and experiment. It also provided valuable clues because it could be tweaked to see what elements were required to trigger the panic.
This test script starts a (vnet) jail, adds an epair interface to it, sets up pf in the jail, and then reloads the pf rules on the host. Interestingly the panic does not seem to occur if that last step is not included.
Time to take a closer look at the code that breaks:
u_int32_t
pf_state_expires(const struct pf_state *state)
{
u_int32_t timeout;
u_int32_t start;
u_int32_t end;
u_int32_t states;
/* handle all PFTM_* > PFTM_MAX here */
if (state->timeout == PFTM_PURGE)
return (time_uptime);
KASSERT(state->timeout != PFTM_UNLINKED,
("pf_state_expires: timeout == PFTM_UNLINKED"));
KASSERT((state->timeout < PFTM_MAX),
("pf_state_expires: timeout > PFTM_MAX"));
timeout = state->rule.ptr->timeout[state->timeout];
if (!timeout)
timeout = V_pf_default_rule.timeout[state->timeout];
start = state->rule.ptr->timeout[PFTM_ADAPTIVE_START];
if (start) {
end = state->rule.ptr->timeout[PFTM_ADAPTIVE_END];
states = counter_u64_fetch(state->rule.ptr->states_cur);
} else {
start = V_pf_default_rule.timeout[PFTM_ADAPTIVE_START];
end = V_pf_default_rule.timeout[PFTM_ADAPTIVE_END];
states = V_pf_status.states;
}
if (end && states > start && start < end) {
if (states < end)
return (state->expire + timeout * (end - states) /
(end - start));
else
return (time_uptime);
}
return (state->expire + timeout);
}
Specifically, the following line:
states = counter_u64_fetch(state->rule.ptr->states_cur);
We try to fetch a counter value here, but instead we dereference a bad pointer. There's two here, so already we need more information. Inspection of the core dump reveals that the state pointer is valid, and contains sane information. The rule pointer (rule.ptr) points to a sensible location, but the data is mostly 0xdeadc0de. This is the memory allocator being helpful (in debug mode) and writing garbage over freed memory, to make use-after-free bugs like this one easier to find.
In other words: the rule has been free()d while there was still a state pointing to it. Somehow we have a state (describing a connection pf knows about) which points to a rule which no longer exists.
The core dump also shows that the problem always occurs with states and rules in the default vnet (i.e. the host pf instance), not one of the pf instances in one of the vnet jails. That matches with the observation that the test script does not trigger the panic unless we also reload the rules on the host.
Great, we know what's wrong, but now we need to work out how we can get into this state. At this point we're going to have to learn something about how rules and states get cleaned up in pf. Don't worry if you had no idea, because before this bug I didn't either.
The states keep a pointer to the rule they match, so when rules are changed (or removed) we can't just delete them. States get cleaned up when connections are closed or they time out. This means we have to keep old rules around until the states that use them expire.
When rules are removed pf_unlink_rule() adds then to the V_pf_unlinked_rules list (more on that funny V_ prefix later). From time to time the pf purge thread will run over all states and mark the rules that are used by a state. Once that's done for all states we know that all rules that are not marked as in-use can be removed (because none of the states use it).
That can be a lot of work if we've got a lot of states, so pf_purge_thread() breaks that up into smaller chuncks, iterating only part of the state table on every run. Let's look at that code:
void
pf_purge_thread(void *unused __unused)
{
VNET_ITERATOR_DECL(vnet_iter);
u_int idx = 0;
sx_xlock(&pf_end_lock);
while (pf_end_threads == 0) {
sx_sleep(pf_purge_thread, &pf_end_lock, 0, "pftm", hz / 10);
VNET_LIST_RLOCK();
VNET_FOREACH(vnet_iter) {
CURVNET_SET(vnet_iter);
/* Wait until V_pf_default_rule is initialized. */
if (V_pf_vnet_active == 0) {
CURVNET_RESTORE();
continue;
}
/*
* Process 1/interval fraction of the state
* table every run.
*/
idx = pf_purge_expired_states(idx, pf_hashmask /
(V_pf_default_rule.timeout[PFTM_INTERVAL] * 10));
/*
* Purge other expired types every
* PFTM_INTERVAL seconds.
*/
if (idx == 0) {
/*
* Order is important:
* - states and src nodes reference rules
* - states and rules reference kifs
*/
pf_purge_expired_fragments();
pf_purge_expired_src_nodes();
pf_purge_unlinked_rules();
pfi_kif_purge();
}
CURVNET_RESTORE();
}
VNET_LIST_RUNLOCK();
}
pf_end_threads++;
sx_xunlock(&pf_end_lock);
kproc_exit(0);
}
We iterate over all of our virtual pf instances (VNET_FOREACH()), check if it's active (for FreeBSD-EN-17.08, where we've seen this code before) and then check the expired states with pf_purge_expired_states(). We start at state 'idx' and only process a certain number (determined by the PFTM_INTERVAL setting) states. The pf_purge_expired_states() function returns a new idx value to tell us how far we got.
So, remember when I mentioned the odd V_ prefix? Those are per-vnet variables. They work a bit like thread-local variables. Each vnet (virtual network stack) keeps its state separate from the others, and the V_ variables use a pointer that's changed whenever we change the currently active vnet (say with CURVNET_SET() or CURVNET_RESTORE()). That's tracked in the 'curvnet' variable. In other words: there are as many V_pf_vnet_active variables as there are vnets: number of vnet jails plus one (for the host system).
Why is that relevant here? Note that idx is not a per-vnet variable, but we handle multiple pf instances here. We run through all of them in fact. That means that we end up checking the first X states in the first vnet, then check the second X states in the second vnet, the third X states in the third and so on and so on.
That of course means that we think we've run through all of the states in a vnet while we really only checked some of them. So when pf_purge_unlinked_rules() runs it can end up free()ing rules that actually are still in use because pf_purge_thread() skipped over the state(s) that actually used the rule.
The problem only happened if we reloaded rules in the host jail, because the active ruleset is never free()d, even if there are no states pointing to the rule.
That explains the panic, and the fix is actually quite straightforward: idx needs to be a per-vnet variable, V_pf_purge_idx, and then the problem is gone.
As is often the case, the solution to a fairly hard problem turns out to be really simple.
posted at: 19:00 | path: /freebsd | [ 0 comments ]